
Treap = Tree + Heap
二叉搜索树(BST)
在学习 Treap 之前,需要先了解一下二叉搜索树(BST, Binary Search Tree):
设 $x$ 是二叉搜索树中的一个结点。如果 $y$ 是 $x$ 左子树中的一个结点,那么 $y.key \lt x.key$。如果 $y$ 是 $x$ 右子树中的一个结点,那么 $y.key \gt x.key$。
BST 上的基本操作所花费的时间与这棵树的高度成正比。对于一个有 $n$ 个结点的二叉搜索树中,这些操作的最优时间复杂度为 $O(\log n)$,最坏为 $O(n)$。随机构造这样一棵二叉搜索树的期望高度为 $O(\log n)$。然而,当这棵树退化成链时,则同样的操作就要花费 $O(n)$ 的最坏运行时间。
由于普通 BST 容易退化,对于它的实现就不再赘述。在实践中需要使用如 Treap 这样的平衡二叉搜索树。
Treap
顾名思义,Treap 是树和堆的结合。它的数据结构既是一个二叉搜索树,又是一个二叉堆。
在 Treap 的每个结点中,除了 $key$ 值,还要保存一个 $fix$(更常见的是 $priority$)值。这个值是随机值,以它为依据来同时建立最大堆(或最小堆)。因为 $fix$ 值是随机的,所以可以让这棵树更加平衡,高度更接近 $O(\log n)$。它的各种操作期望时间复杂度都是 $O(\log n)$。
旋转式 Treap
旋转式 Treap 的常数较小。
旋转
左旋/右旋操作不会破坏 BST 的性质,并可以通过它来维护堆,使树平衡。
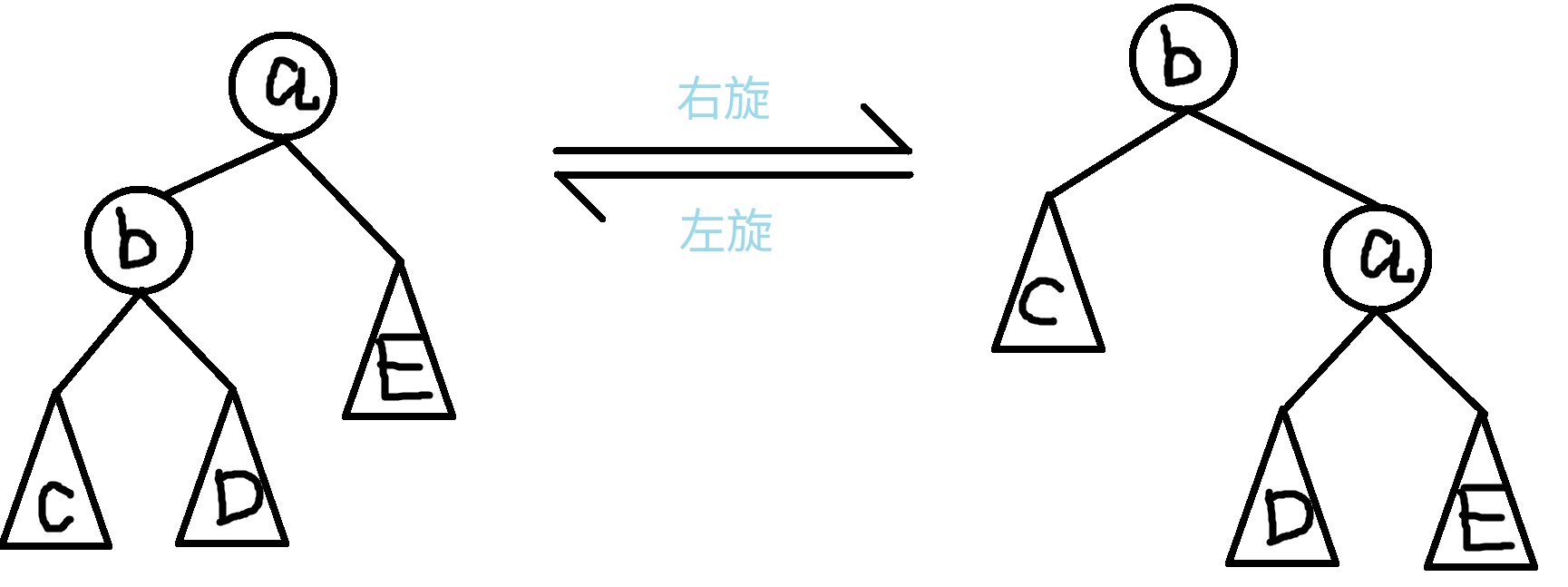
如图,以右旋为例。假设现在左边树 $b$ 的 $fix$ 值大于 $a$ 的 $fix$ 值,然而 $b$ 是 $a$ 的儿子,那么就不符合最大堆的性质,需要进行右旋,变成了右边的树。
但是为什么在旋转的过程中没有破坏 BST 的性质呢?设 $c \in C, d \in D, e \in E$。由左树知 $c \lt b \lt d \lt a \lt e$。再由旋转之后树的结构可以得出 $c \lt b \lt d \lt a \lt e$,这两个式子是一样的。所以,这棵树依然是 BST。
在插入和删除操作中都要按需进行旋转操作。
插入
根据 BST 的性质,找到相应的位置创建新叶子结点就可以了。如果不符合最大堆性质,进行旋转操作。
删除
删除一个元素时,可以对被删除的结点分类讨论:
- 没有子结点:直接就成空的了
- 只有一个子结点:把被删除结点设成它仅有的儿子即可
- 有两个子结点:选出两个儿子中 $fix$ 值较大的一个,通过旋转操作把它设成新的根,这样要删除的结点就只有一个儿子了,按照情况 2 处理。这种方法保证满足了 BST 和最大堆的性质。
在程序实现时,实际上情况 1 和 2 的代码是一样的,所以只用分两类。
以 P3369 【模板】普通平衡树 - 洛谷 为例,代码如下。
| |
无旋 Treap
无旋 Treap 的核心操作是分裂、合并。
分裂(Split)
分裂操作会将原 Treap 一分为二,第一个 Treap 中的结点关键值都小于等于 $key$,第二个中都大于 $key$。使用递归实现。
若当前关键值大于 $key$,那么当前结点连同右子树都属于第二个 Treap,继续往左子树递归。
若当前关键值小于等于 $key$,那当前结点连同左子树都属于第一个 Treap。继续往右子树递归。

| |
合并(Merge)
合并函数接受两棵树,其中第一棵的值都小于第二棵。每一次根据两棵树的根的 $fix$ 值来确定新树的根,然后递归合并子树。
当两棵树任何一个为空时,返回另一个。

| |
插入
将树分裂成两个部分:$A=\lbrace x \mid x \le key \rbrace$、$B= \lbrace x \mid x \gt key \rbrace$,先将要插入的值合并入 $A$,最后合并 $A$ 和 $B$。

| |
删除
将树分裂成三个部分:$A= \lbrace x \mid x \lt key \rbrace$、$B= \lbrace x \mid x = key \rbrace$、$C= \lbrace x \mid x \gt key \rbrace$,然后合并 $A$ 和 $C$。

| |
致谢: